
Распределенные Базы И Хранилища Данных Департамент Программной Инженерии Национальный Исследовательский Университет «высшая Школа Экономики»
Что касается блочных технологий Huawei, они уже сейчас поддерживают FC-NVMe (NVMe over Fibre Channel), и на подходе NVMe over RoCE (RDMA ecn счета форекс over Converged Ethernet). Тестовые модели вполне функциональны, до официальной их презентации осталось несколько месяцев. Заметим, что всё это появится и в распределённых системах, где «Ethernet без потерь» будет весьма востребован. Если ваша компания хранит данные, к которым не нужен каждодневный доступ, но которые необходимо хранить в течение длительного времени, например, согласно требованиям законодательства, то имеет смысл использовать механизм архивного хранения. В большинстве случаев, «холодное» хранение данных дешевле «горячего» хранения. Под самоорганизацией (Self-management) систем понимается процесс, при котором компьютерные системы управляют своей собственной работой без человеческого вмешательства.
Распределенная Система Хранения Данных: Типы И Реальные Примеры
Его применяют в таких форматах данных, как GIF и TIFF, что делает его весьма популярным для графических файлов. Однако его эффективность снижается при работе с высоко динамичными данными, что требует разработки более сложных решений для динамических потоков данных. В то же время LZW продолжает оставаться одним из самых востребованных алгоритмов для компрессии в системах, где данные поддаются сжатию с минимальными потерями. В таблице 2 представлены основные методы оптимизации данных, их преимущества и недостатки. Эти методы широко применяются в распределенных хранилищах для улучшения производительности и уменьшения объемов хранения данных. Распределенное хранение данных (Distributed Storage) – это концепция хранения информации, при которой файлы разбиваются на фрагменты и распределяются по различным узлам (серверам) в сети.
В отличие от статической, динамическаяреорганизация базы данных не требует остановки работы системы и обеспечиваетплавный переход к новому размещению данных. Существенно, чтобы реорганизациябыла прозрачна для откомпилированных программ, работающих в параллельнойсистеме. В частности, она не должна приводить к необходимости перекомпиляциипрограмм. Это значит, что откомпилированные программы не должны зависеть от размещения данных. Множество узлов, на которых выполняетсяоперация, называется домашним множеством операции.

Хранилище данных как система как раз предоставляет инфраструктуру и инструменты для эффективного выполнения этих функций. По этой причине сегодня темы по проектированию архитектуры хранилищ данных настолько востребованы и актуальны. Тем не менее, внедрение распределенных систем хранения данных связано с определенными вызовами. Обеспечение согласованности данных требует наличия надежных механизмов, способных справляться с потенциальными конфликтами и задержками, возникающими при передаче данных.
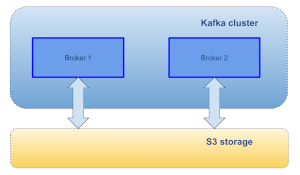
Будущее Распределенных Файловых Систем
Управление количеством дублированных блоков должно учитывать важность данных. Это обеспечивает оптимальное соотношение между надёжностью и затратами. Вместо традиционных схем, применяющих одинаковое число копий, используются алгоритмы, которые позволяют адаптировать количество реплик к особенностям данных. В1оош Filter Структура данных, использующая хеш-функции для проверки наличия элемента в наборе данных. Возможность ложных срабатываний, неэффективен при больших объемах данных. Для хранения большого объёма данных они сохраняются в колоночном формате Parquet с использованием табличного формата Iceberg для организации эффективного доступа к ним.
- Поскольку информация распределена по нескольким узлам, нет эффекта блокировки поставщика.
- Его сервера по приказу спецслужб США были физически «вырублены» провайдером LeaseWeb с последующей конфискацией.
- Платформа была разработана еще в 2010 году и позиционировалась как протокол схожий с торрентом.
- В узле,где инициируется транзакция, создается процесс-координатор (coordinator); во всехпрочих затрагиваемых ею узлах создаются процессы-участники (participant).
- ELT является предпочтительным подходом для Knowledge Lakes для работы с большим объёмом неструктурированных или полуструктурированных данных.
Для дальнейшего https://www.xcritical.com/ повышения эффективности работы распределенных хранилищ данных разработаны методы сжатия информации, которые способствуют экономии ресурсов. Эти технологии позволяют уменьшить объем данных, которые необходимо хранить, без потери их целостности и актуальности 2. Важно отметить, что подходы к сжатию данных должны быть адаптированы к конкретным типам хранилищ, поскольку различные системы предъявляют разные требования к обработке данных. В частности, в системах, использующих облачные хранилища, могут применяться другие методы сжатия и оптимизации, чем в традиционных файловых системах. В статье рассматриваются актуальные методы и технологии, применяемые для оптимизации хранения данных в распределенных хранилищах.
До того, как начинать установку, рекомендуется подготовить для нее все необходимое.Количество и мощность железа напрямую зависит от того, сколько и каких сред потребуется развернуть. Для целей разработки можно установить все компоненты хоть на распределенные хранилища данных одну хилую виртуалку, но такой подход не приветствуется. Влиять на такие параметры, как архитектура, кроссплатформен-ность, окружение и объектное хранение, скорее всего, не получится и нет смысла, т.к. Они являются концептуальными, системообразующими, от которых будут зависеть остальные функции и механизмы.